Understanding JMH: Java Microbenchmark Harness Made Simple
In the world of software development, performance matters. But how do we accurately measure and compare the performance of different implementations? This is where JMH (Java Microbenchmark Harness) comes into play. In this post, we'll explore JMH through a practical example of benchmarking trace ID generation methods.
What is JMH?
JMH is a Java harness for building, running, and analyzing nano/micro/milli/macro benchmarks written in Java and other languages targeting the JVM. It was developed by the OpenJDK team and is used extensively in the JDK itself to perform performance testing.
Setting Up JMH with Gradle
To get started with JMH, you'll need to add the necessary dependencies to the build configuration. Here's how to set it up in a Gradle project:
plugins {
id 'java'
id 'me.champeau.jmh' version '0.7.1'
id 'io.morethan.jmhreport' version '0.9.0'
}
dependencies {
implementation 'org.openjdk.jmh:jmh-core:1.37'
implementation 'org.openjdk.jmh:jmh-generator-annprocess:1.37'
}
jmh {
resultFormat = 'JSON'
resultsFile = layout.buildDirectory.file('reports/jmh/results.json').get().asFile
jmhVersion = '1.37'
timeUnit = 'ns'
threads = project.hasProperty('jmh.threads') ? project.property('jmh.threads').toInteger() : 1
}Writing JMH Benchmarks
Let's look at a real-world example where we benchmark two different approaches to generating trace IDs: using UUID
and using OpenTelemetry's IdGenerator.
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Thread)
@Warmup(iterations = 5, time = 1)
@Measurement(iterations = 10, time = 1)
@Fork(2)
public class TraceIdGeneratorBenchmark {
private IdGenerator otelIdGenerator;
@Setup
public void setup() {
otelIdGenerator = IdGenerator.random();
}
@Benchmark
public void uuidBasedTraceId(Blackhole blackhole) {
String traceId = UUID.randomUUID().toString();
blackhole.consume(traceId);
}
@Benchmark
public void openTelemetryTraceId(Blackhole blackhole) {
String traceId = otelIdGenerator.generateTraceId();
blackhole.consume(traceId);
}
}Understanding JMH Annotations
Let's break down the key JMH annotations:
@BenchmarkMode: Specifies what to measure. In our example, we measure average time(Mode.AverageTime).@OutputTimeUnit: Defines the unit for the results. In our example it is in nanoseconds(TimeUnit.NANOSECONDS).@State: Defines the scope of our benchmark state (Thread scope means each thread has its own copy).@Warmup: This annotation controls the "warm-up" phase of the benchmark. Before JMH starts collecting actual performance data, it runs the benchmark code several times to allow the Java Virtual Machine (JVM) to reach a "steady state."-
iterations = 5means JMH will run 5 warm-up iterations. -
time = 1indicates that each of these 5 warm-up iterations will run for 1 second. During this second, JMH will execute the benchmark method as many times as possible.
The results from these warm-up runs are discarded, ensuring that the subsequent measurements reflect the performance of fully optimized code. Those warmup cycles take care of the below:
- JIT Compilation: The JVM's Just-In-Time (JIT) compiler needs time to identify "hot" code paths and optimize them into highly efficient machine code. The first few executions of a method are often much slower than subsequent ones.
- Class Loading: Classes need to be loaded into memory, which incurs a one-time cost.
-
@Measurement: This annotation defines the actual "measurement" phase, which begins immediately after the warm-up phase concludes. This is where JMH collects the data that will be used to generate the benchmark report.iterations = 10specifies that JMH will perform 10 separate measurement iterations. Each of these iterations will produce a single data point (a performance score).time = 1indicates that each of these 10 measurement iterations will run for 1 second. During this second, JMH will execute the benchmark method as many times as possible.
The benchmark score (e.g. Average Time) and its associated error margin are calculated from the statistical analysis of these 10 collected data points.
@Fork: Indicates how many separate JVM forks to use (helps eliminate external factors). With a value of2in the@Forkannotation, the entire benchmark would run on 2 different JVM forks. This means the final benchmark score is calculated from the statistical analysis of 20 collected data points (10 from each fork), providing a more robust and reliable performance metric.
Running the Benchmark Project
Let's walk through setting up and running our trace ID generator benchmark project:
Project Setup
# Clone the repository
git clone https://github.com/GSSwain/benchmark-trace-id-generator.git
cd benchmark-trace-id-generatorUnderstanding the Project Structure
The benchmark project includes:
- JMH configuration in
build.gradle - Benchmark implementation in
src/jmh/java - Two trace ID generation methods:
- UUID-based: Using Java's built-in
UUIDgenerator - OpenTelemetry: Using OpenTelemetry's
RandomIdGenerator
- UUID-based: Using Java's built-in
Understanding the Benchmark report
After running the benchmarks, JMH produces a detailed report. Here's a breakdown of what each column means:
- Benchmark: The name of the benchmark method being tested.
- Mode: The measurement mode. In our case,
avgtstands for Average Time. - Cnt: The total number of measurement iterations (Forks × Measurement Iterations). In our setup, this is 2 forks × 10 iterations = 20 runs.
- Score: The measured performance value. For average time, a lower score is better.
- Error: The statistical error margin for the score. A smaller error indicates more stable and reliable results.
- Units: The unit of the score, which is
ns/op(nanoseconds per operation) in our configuration.
Single-Thread Performance (1 Thread, JDK 25)
# Run the benchmark with single thread on Java 25
./gradlew clean jmh -PjavaVersion=25Console output
Benchmark Mode Cnt Score Error Units
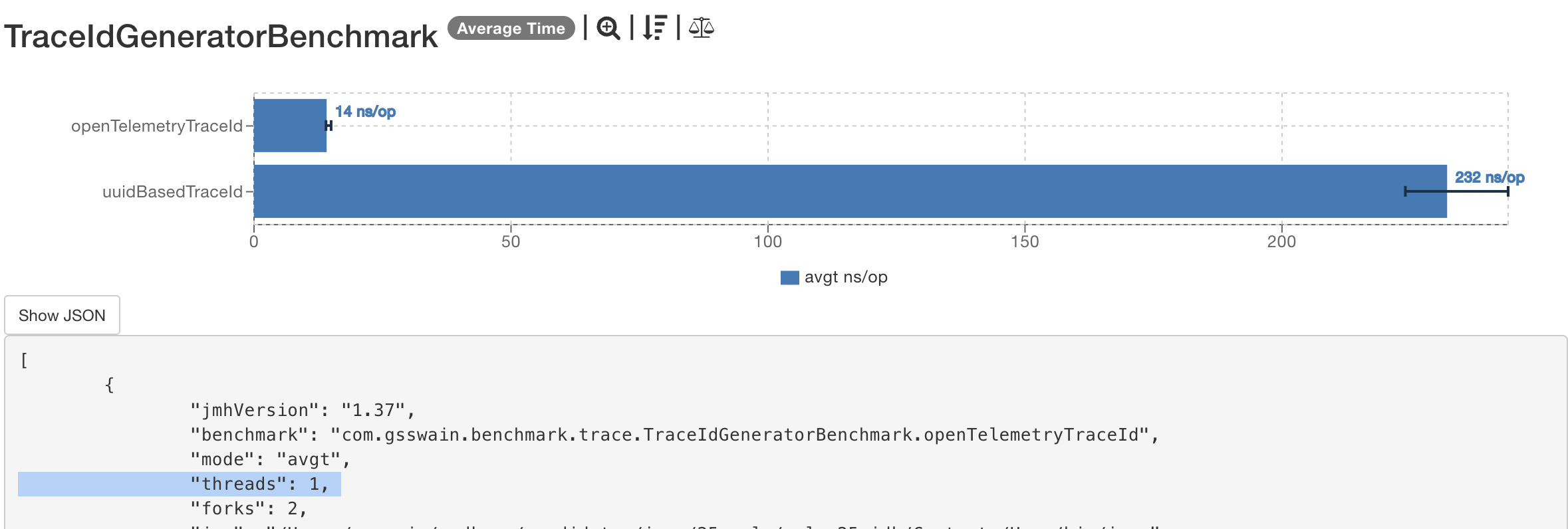
TraceIdGeneratorBenchmark.openTelemetryTraceId avgt 20 14.675 ± 0.123 ns/op
TraceIdGeneratorBenchmark.uuidBasedTraceId avgt 20 237.660 ± 2.242 ns/op
# Generate html report with single thread on Java 25
./gradlew clean jmhReport -PjavaVersion=25html output
Multi-Thread Performance (10 Threads, JDK 25)
# Run with multiple threads on Java 25 (e.g. 10 threads)
./gradlew clean jmh -PjavaVersion=25 -Pjmh.threads=10Console output
Benchmark Mode Cnt Score Error Units
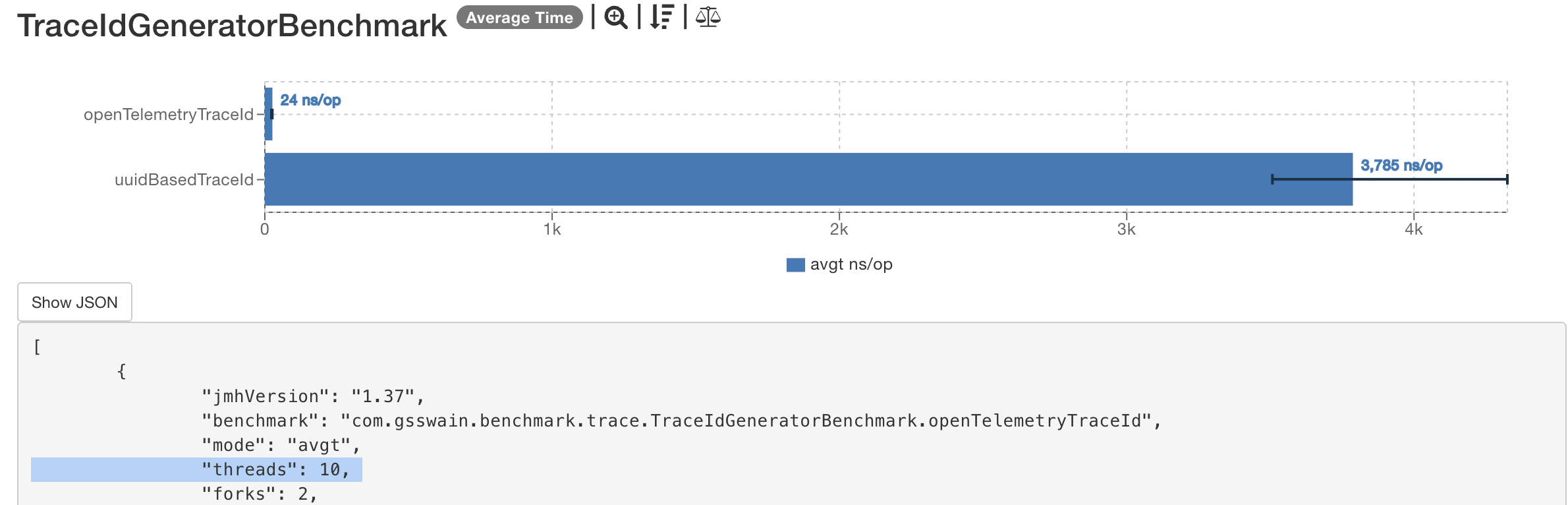
TraceIdGeneratorBenchmark.openTelemetryTraceId avgt 20 24.478 ± 1.215 ns/op
TraceIdGeneratorBenchmark.uuidBasedTraceId avgt 20 3784.821 ± 133.956 ns/op
# Generate html report with multiple threads on Java 25 (e.g. 10 threads)
./gradlew clean jmhReport -PjavaVersion=25 -Pjmh.threads=10html output
Interpreting These Results
Let's break down what these numbers tell us:
1. Single-Thread Analysis
- Average Time:
OpenTelemetry: ~14.6 nanoseconds per operationUUID: ~237.6 nanoseconds per operationOpenTelemetryis approximately 16x faster compared toUUID.
2. Multi-Thread Analysis (10 Threads)
- Average Time:
OpenTelemetry: Only increases to ~25 nanoseconds (1.7x increase)UUID: Jumps to ~3,784 nanoseconds (~16x increase)OpenTelemetryis approximately 150x faster compared toUUIDin a multithreaded environment with 10 threads.
3. Key Observations
- Thread Scaling:
OpenTelemetry: The average time per operation sees only a minor increase (from ~14.7 ns to ~24.5 ns) when moving from 1 to 10 threads, demonstrating excellent scaling under contention.UUID: The average time per operation increases dramatically (from ~238 ns to ~3785 ns), indicating significant performance degradation and poor scaling under contention.
- Consistency:
OpenTelemetryhas very small error margins (±0.123 to ±1.215), indicating consistent performance.UUIDshows much larger variations (±2.242 to ±133.956), especially under load.
For a complete breakdown of the results across different JDK versions and a deeper analysis of the real-world impact, please see the follow-up post: Trace ID Generation: A Performance Analysis of UUID vs. OpenTelemetry.
Best Practices
When writing JMH benchmarks, keep these points in mind:
- Use
Blackhole.consume()to prevent dead code elimination - Include proper warmup iterations to ensure JVM optimization
- Run multiple forks to get statistically significant results
- Consider external factors like garbage collection and JIT compilation
- Document the benchmark environment (JVM version, available processors, etc.)
Conclusion
JMH is a powerful tool for measuring and comparing code performance on the JVM. While it requires careful setup and interpretation, it provides valuable insights into code performance characteristics. Remember that microbenchmarks should be one of many tools in the performance testing arsenal, alongside profiling and real-world performance testing.
The example used in this post can be found in the benchmark-trace-id-generator repository.